
Introduction to Data Sync#
Overview#
Data syncs can be performed from within Automate or directly on a device. For this reason, cached Automate data should be periodically synced with data on devices.
Examples:
When an instance of a CUCM is added to the system, its data is imported and cached.
When instances are added, updated, or deleted from the CUCM, the cached data in Automate becomes out of sync with data on the device.
When deleting data from CUCM before deleting it from Automate, the system displays the following error: “The specified resource could not be found”
This means the resource is out of sync, and Automate may need to re-sync with CUCM in order to delete it or update it.
Automate data syncs allow you to dynamically synchronize cached Automate data with data on devices. The data sync instance is associated with the connection parameters of a device type in Automate.
Supported devices include:
Cisco Unified CM (CUCM)
Cisco Unity Connection (CUC)
LDAP
WebEx
MSTeamsOnline (Microsoft Teams)
MSGraph
Individual add, update, and delete operations carried out by a data sync instance can be disabled on the user interface. If no operation is selected, the default behavior is maintained.
Related Topics
Data Sync Settings#
To view the summary list of configured data syncs in Automate, go to (default menus) Administration Tools > Data Sync. The list view displays basic details for each available data sync, including a number of summary attributes that provide additional details about the data sync.
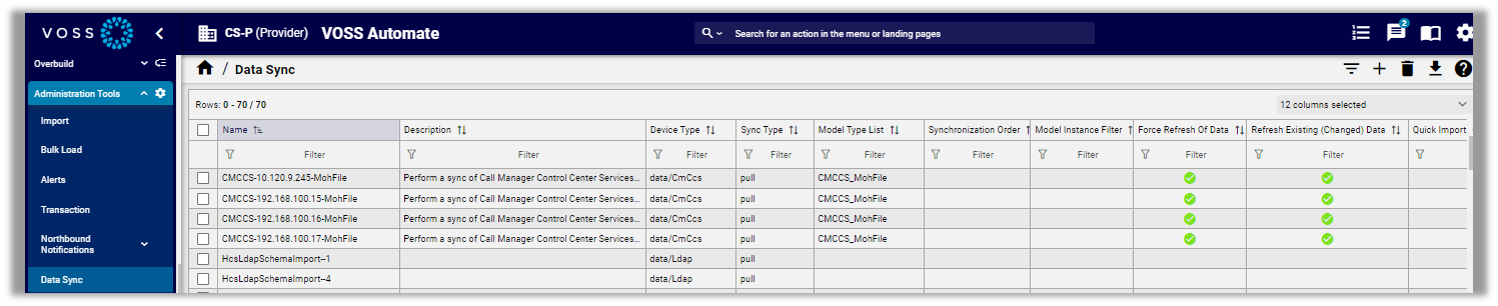
To view data sync settings, click on a data sync in the list to open the configuration page.
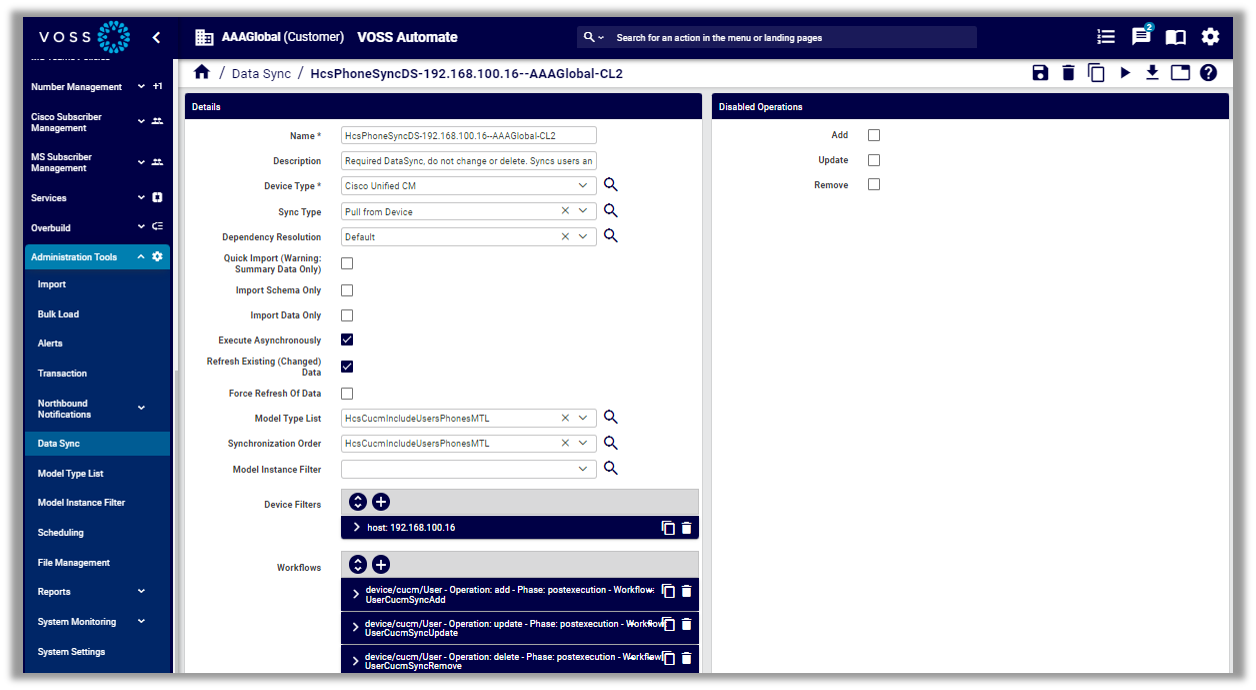
The table describes a number of key settings that are available for data syncs:
Settings |
Description |
|---|---|
Model Type lists |
Define the entities to pull in a given sync. For example:
|
Model Instance filters |
Limit a sync to a subset of entities in a sync. For example:
A system-level administrator will need to expose this setting in the Admin Portal. |
Disabled Operations |
Choose which operations are enabled for a sync (Add/Update/Remove).
To save time on the sync, you may wish to disable Update if you only require Add/Delete. Important Remove is disabled by default if you’ve selected a model instance filter for the sync. You’ll need to enable Remove if you intend for the sync to purge (remove) cache records that are excluded in the model instance filter. If you’re upgrading to 21.4-PB4 from an earlier version of Automate, a migration script disables Remove for any syncs that have a model instance filter applied. This is to prevent the sync from unexpectedly removing a large number of records after the upgrade. |
Quick Import |
Uses the list API responses to update the Automate cache, and won’t perform individual GET calls for each entity for the update. Recommended when the list response contains all values for the entity, or where only the key settings must be updated. Removing individual GETs speeds up the sync, since Automate is not waiting for the API responses when there are a many entities to update. This is useful if the list and GET responses are required, or if you only need the summary data from the list view. This setting is disabled by default for syncs related to device/spark/user syncs (SyncSparkUsers and SyncSpark). |
Note
Quick Imports can improve sync performance but must be used with extreme caution to avoid unintended changes. Typically, Quick Import is recommended only for Microsoft-related data syncs (MSOperatorConnect, MSGraph, MSTeamsOnline, MSExchangeOnline) and for Webex App/Teams-related syncs that do not include the Webex App/Teams user (device/Spark/user).
The default Full Sync instance provided for CUC also does not have Quick Import enabled.
Synchronous and Asynchronous Data Sync#
By default, a data sync is asynchronous; that is, other tasks can be carried out while the sync is in progress.
However, a data sync can be set to be synchronous so that a workflow step can, for example, wait for the sync process to complete.
Asynchronous imports initiated by a data sync are standalone transactions; that is, they aren’t child transactions of the data sync execute transaction. Synchronous imports initiated by a data sync are children of the data sync execute transaction.